40Ashkenazim: Collection of the data, analysis, simulation
An inspection on the quality of the data and a comparison with other countries
Data collection
The data is collected in a systematic way:
- A branch is recognized as an Ashkenazi branch if at least two members with different surnames are reported Ashkenazi. The majority of the group must
be reported as Ashkenazi.
- The data are collected using semargl.me. This site collects data of people from ftdna.com, ysearch.com in a systematic way. In some cases people are removed from the
database on request. The removal will not depend on a value for STR or on a specific branch, it is not expected to a have systematic effects.
Due to the use of ftdna.com the percentage will be larger in some countries than others, e.g. larger in the United Kingdom than France. However, it is expected
that it will influence all branches the same.
- The data are reported in different countries of origin. The following definition is used:
- Eastern Europe: "Ukraine","Poland","Russia","Lithuania","Latvia","Hungary","Romania","Belarus","Moldova"
- Germanic countries: "Germany", "Netherlands", "Austria", "Czech Republic"
- Southern Europe: "Spain","Italy","Portugal","Mexico","Puerto Rico"
- Middle East: "Saudi Arabia","Kuwait","United Arab Emirates","Lebanon","Egypt","Qatar","Oman","Yemen","Armenia","Iraq", "Libya"
- Britain and Ireland: "United Kingdom","Ireland"
- Unknown: the person did not indicated where his male line ancestor came from
- Other countries: they are reported
This grouping of countries is chosen, since it represents possible elements in the history of the Ashkenazi Jews. Puerto Rico and Mexican are
mentioned in the group of Spain, Portugal, since several reports of people that were Jewish in Golden Era of Jews in Spain moved to these locations.
The choices above where checked below to see if that choice is consistent with the observed data.
Data analysis
Data analysis of each branch
For each branch the data was analysed in a uniform way.
- A modal was determined for each group. This was used to determine the tmrca of the group. In case the collection of the group is not homogeneous,
it will influence the value of the tmrca.
- For each branch a maximum number of steps was determined. This is the amount of steps that determines whether a person is considered an element of the
Ashkenazi branch or not. This is done by hand, which gives the method a subjective element. In the diagrams the maximum number of steps is indicated. It can be seen
that for most branches it is well determined. In the case of very small branches, one might argue that the value might be one smaller or larger.
In a few cases two close branches were found. If the two branches show at least 3 markers difference, they are considered as separate branches.
In the case of these Ashkenazi branches a change of the definition by one marker does not change the branches. This is consistent with the knowledge
that these peoples had a population bottleneck and a successive increase of population (e.g. Behar et al. 2003).
- A best fit was made to determine the tmrca (Time To Most Recent Ancestor). This was done by using the mutation rates of M. Heinila (2013). Using these mutation
rates the chances for the number of mutations is determined. This is done by creating a large table with chances of the number of mutations are one, two, three etc.
number of generations. Suppose we have a dataset of 5 persons with respectively 5,6,6,8 and 9 mutations. The chances that this occurred can be determined after
x generation steps. That gives a chance distribution that a dataset with 5,6,6,8 and 9 mutations occurred as function of number of generations.
Heinila compared his mutation rate with that of Ballantyne et al. (2001), who determined for a few thousand father-son relations the mutations.
A mutation rate of one generation in Heinila should thus be compared with the generation length that was used by Ballantyne. This generation
length was, rounded, 30 years. Recently it was found and confirmed that the amount of SNP mutations between father and son are linear
dependent on the age of the father (Iceland 2012 and research). This indicates that the amount of mutations goes linear with time. It means that two generations of 25 years
give the same number of mutations as one generation of 50 years. For our analysis the Heinila mutation rates should
be used in combination with the generation length of 30 years.
In case the average generation length of the people that were analysed have a longer or shorter average generation length, it does not
influence the calculations.
-
The branch diagrams show the best fit number of generations. It also gives the 2-sigma timerange of tmrca (95% statistical error) expressed in
the moment of birth of the tmrca. It is assumed that the average birth date of the persons of the semargl.me is 1950.
The tmrca time range is determined by calculating asymmetric 1-sigma values, assuming normal distribution, and multiply this by two. It is the intention
that the error ranges will be determined without this assumption, in a later version.
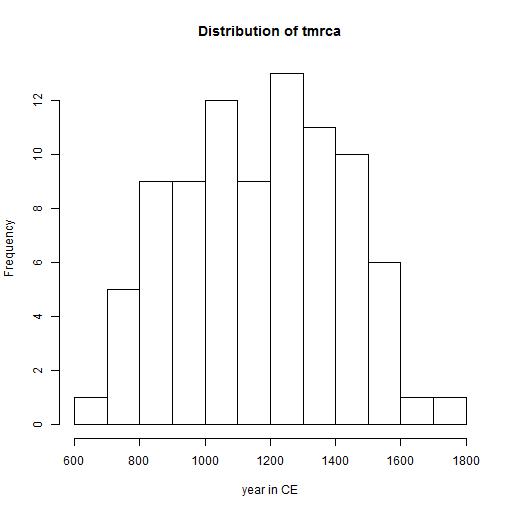
Data analysis on the distribution tmrca
The next diagram shows the distribution of tmrca of the different branches.
Interpretation
The tmrca in this diagram represents the change from population bottleneck to population growth.
It is likely that it is the transition from an area where the change for survival are small to a place where population growth for this group
is large.
The value is probably close to the arrival time in Eastern Europe, where the larger than local population growth was possible. In exceptional cases
it is possible that a large group (with family relations) arrivred in Eastern Europe. In that case the calculated tmrca is a little earlier than the
arrival time in Eastern Europe.
Data analysis on the tmrca as function of size of population
The first diagram shows the relation of logarithm of the size of the group (in our dataset) as function of tmrca.
In this diagram the relation is fitted with a linear fit. The best fit is given as log (size) = 0.0031 * time (in units of ybp).
The result of the fit is shown in the second plot. It gives the same data, with a linear scale for size of the group (in our dataset).
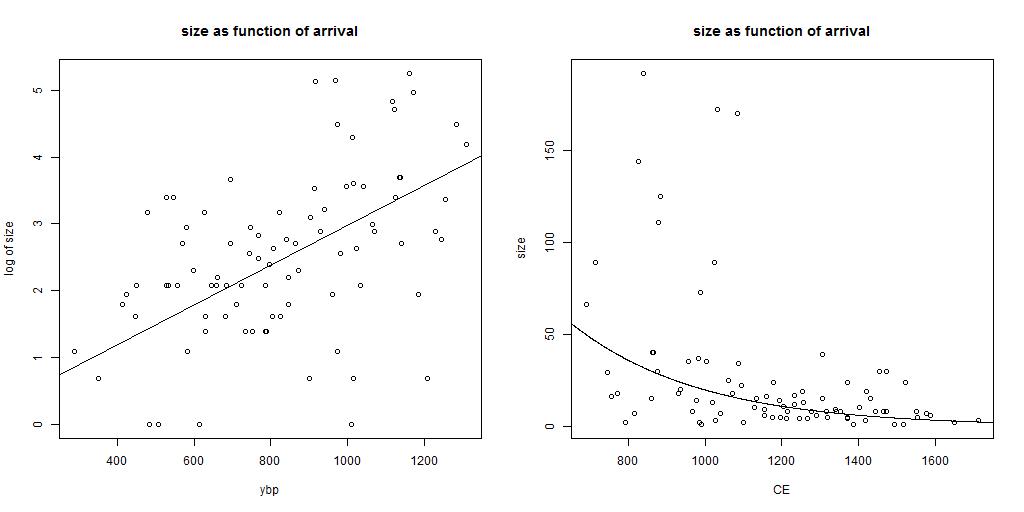
Interpretation
The amount of descendants of a branch is larger if the first ancestor arrived early. In the case that a constant population growth is present (constant in time
and equal for all branches),
one expects a linear relation between logarithm of size as function of tmrca in years before present (ybp).
Due to the large statistical uncertainties in tmrca (and for the small groups also in size) the error range of the relation can not be
determined accurately. The value of 0.0031 gives an average population growth of 0.3% per year (which is 9.7% in 30 years and factor of 1.36
in 100 years). These values are smaller than calculated from the overall data. This is not a surprise. The amount of male lines in the
first years after the mrca have a large statistical impact on the results. Some will have no male lines, some less than average and some will
have more male line descendants than average. A simulation might confirm the lower value for the population growth.
These diagrams confirm that, in general, the larger branches arrived earlier in the area where the population growth was high.
Data analysis on the tmrca as function of size of population
Data analysis on the distribution in countries
In this section we analyse the data on the reported country of origin. In the first diagram they are ordered in order of size.
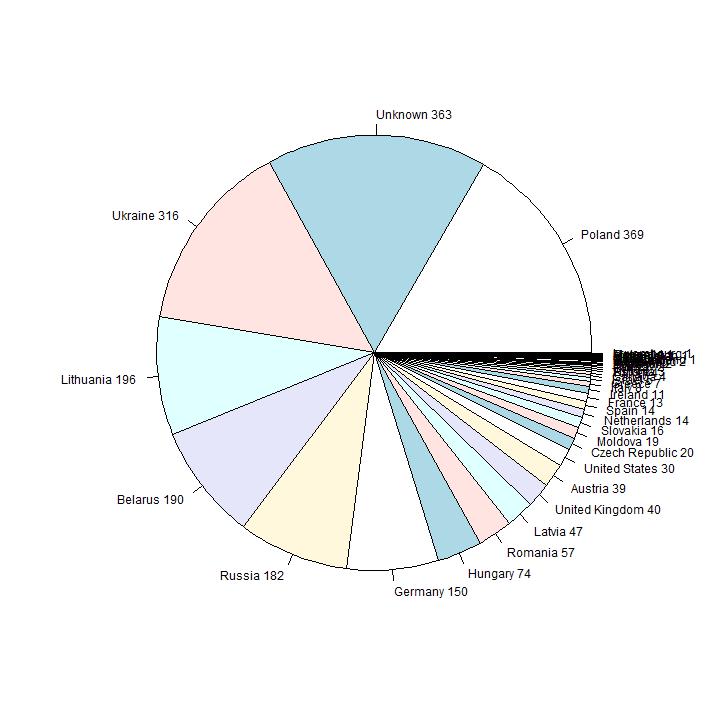
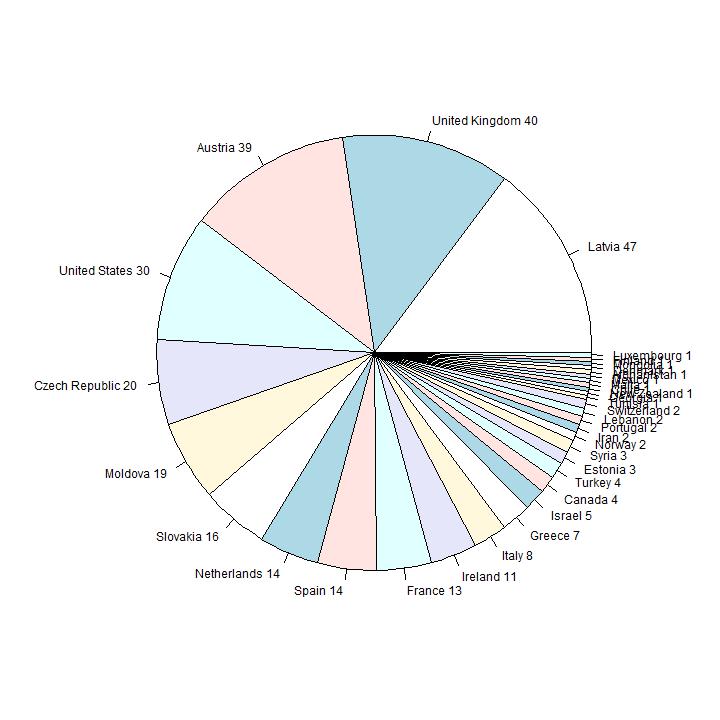
Interpretation
The countries with the highes number of reported people are from well-known Eastern-European Ashkenazi countries. Number six in order of size is
Germany; in the second diagram the first 9 pies are omitted, so the smaller countries are visible. Number 10 in size is United Kingdom (36 persons), 12 is United States
(30 persons).
By statistical coïncidence we would
In this page the data is presented and checked to see if we have systematic
effects in the analysis.
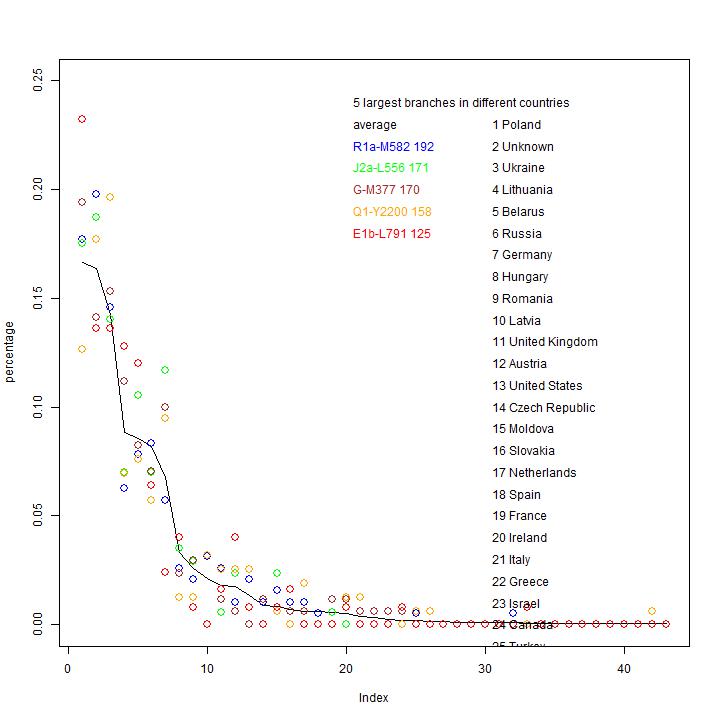
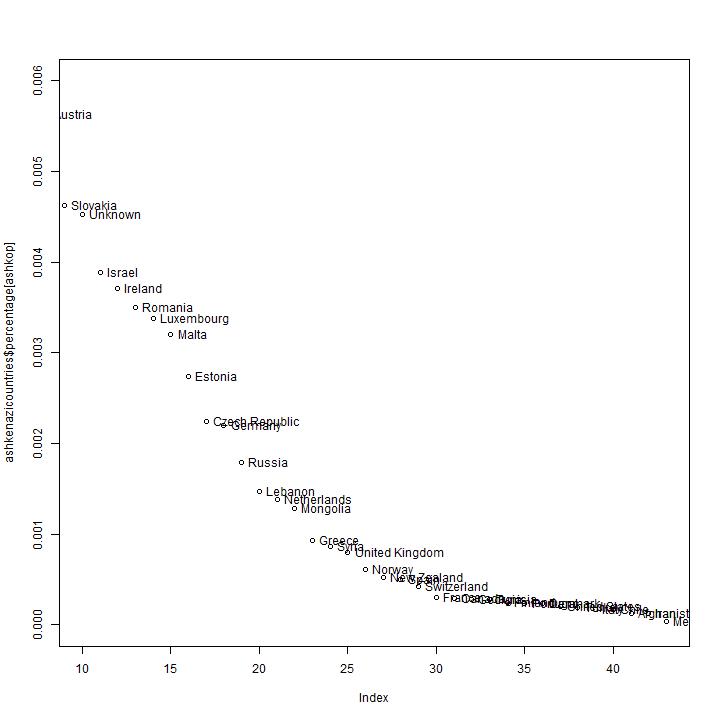
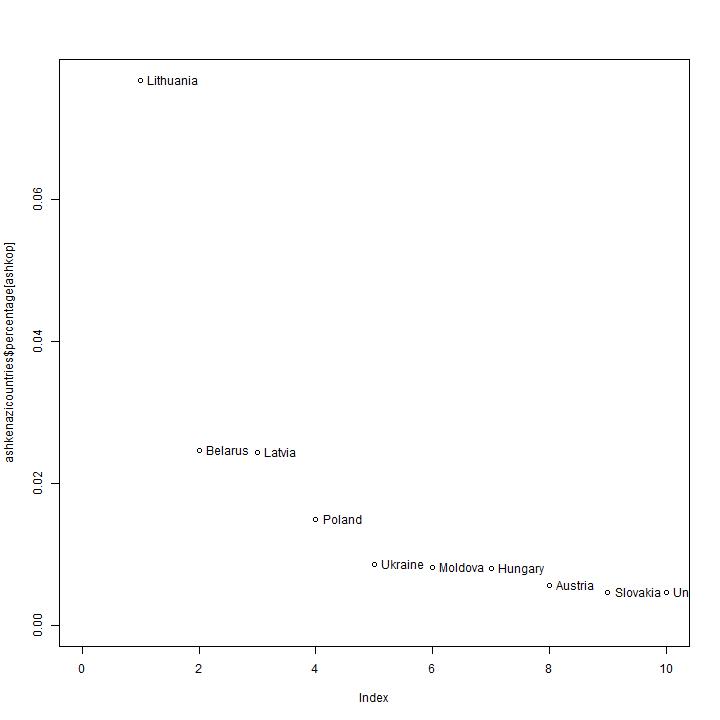

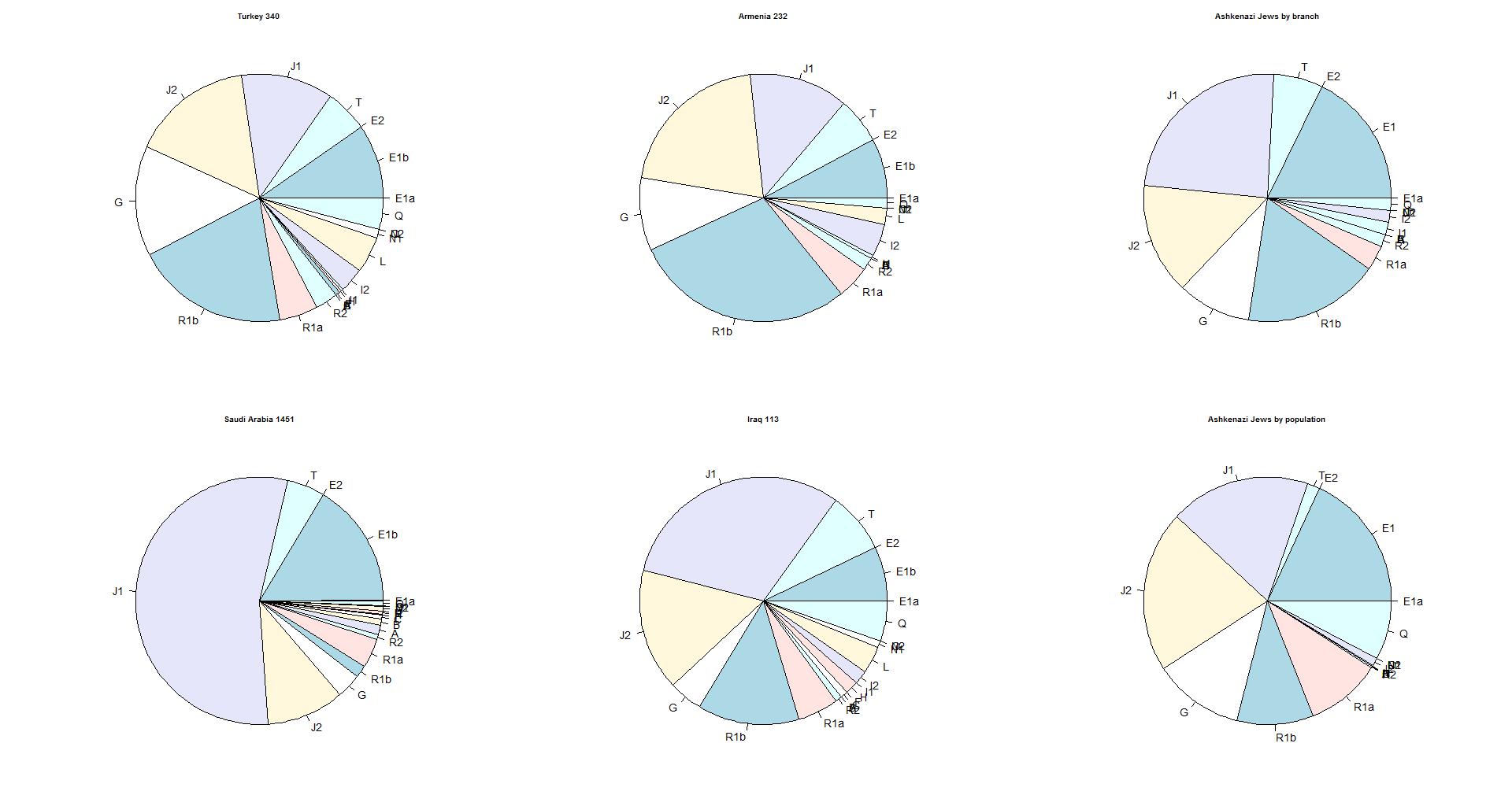
The observed distribution of branches.
A comparison with other countries
The diagram below gives the distribution of 4 countries in comparison with
the percentages of the Ashekenazi Jews. The distribution by branch gives the
best view of the originating area. The distribution by population is strongly
influenced by the order of arriving in the area where the population rate was
high (Polish-Lithuanian area).